Alta disponibilidad con LinuxHA
En estas prácticas se empleará el software de virtualización VIRTUALBOX para simular
pequeñas redes formadas por equipos GNU/Linux.
- Script de instalación
NOTAS:
- Se pedirá un identificador (sin espacios) para poder reutilizar
las versiones personalizadas de las imágenes creadas
(usar por ejemplo el nombre del grupo de prácticas)
- En ambos scripts la variable
$DIR_BASE especifica donde se descargarán las imágenes y se crearán las MVs.
- Por defecto en GNU/Linux será en
$HOME/CDA1516 y en Windows en C:\\CDA1516
- Puede modificarse antes de lanzar los scripts para hacer la instalación en otro directorio más conveniente (disco externo, etc)
- Es posible descargar las imágenes comprimidas manualmente (o intercambiarlas con USB), basta descargar los archivos con extensión
.vdi.zip de http://ccia.ei.uvigo.es/docencia/CDA/1516/practicas
y copiarlos en el directorio anterior ($DIR_BASE) para que el script haga el resto.
- El script descargará las siguientes imágenes en el directorio
DIR_BASE ($HOME/CDA1516 ó C:\\CDA1516)
base_cda.vdi (0,8 GB comprimida, 2,8 GB descomprimida):
Imagen genérica (común a todas las MVs) que contiene las herramientas a utilizar
- Contiene un sistema Debian 7.1 con herramientas gráficas
y un entorno gráfico ligero LXDE (Lighweight X11 Desktop Environment)
[LXDE].
- Usuarios configurados.
| login |
password |
|---|
| root |
purple |
| usuario1 |
usuario1 |
swap1024.vdi: Disco de 1 GB formateado como espacio de intercambio (SWAP)
- (Si no lo hacen desde el script anterior) se pueden arrancar las instancias VIRTUALBOX
desde el interfaz gráfico de VirtualBOX o desde la línea de comandos.
VBoxManage startvm CLIENTE_<id>
VBoxManage startvm SERVIDOR1_<id>
VBoxManage startvm SERVIDOR2_<id>
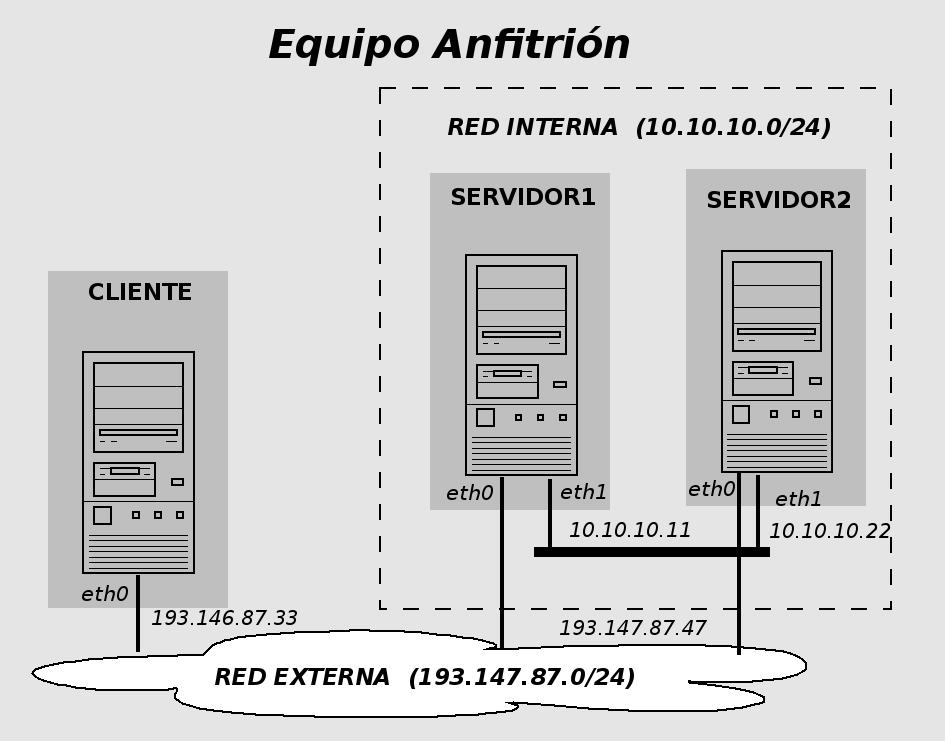
- Una vez ejecutado el script se habrán definido las 2 redes y los 4 equipos virtualizados donde se realizarán los ejercicios:
- Máquinas virtuales
- cliente (193.147.87.33)
- servidor1 (10.10.10.11)
- servidor2 (10.10.10.22)
- Red externa (193.147.87.0 ... 193.147.87.255): máquina cliente (eth0) + interfaz eth0 de servidor1 y servidor2
- Red heartbeat (10.10.10.0 ... 10.10.10.255): máquina servidor1 (eth1) + máquina servidor2 (eth1)
WEB LinuxHA: http://www.linux-ha.org/
Manuales heartbeat:
http://www.linux-ha.org/doc/users-guide/users-guide.html
Manuales pacemaker: http://clusterlabs.org/wiki/Main_Page
- Instalación de LinuxHA en las máquinas del cluster (ya hecho)
apt-get install heartbeat cluster-glue
apt-get install pacemaker resource-agents
- Asignar direcciones IP (con las respectivas direcciones de Broadcast)
servidor1:~# ifconfig eth1 10.10.10.11 netmask 255.255.255.0 broadcast 10.10.10.255 up
servidor2:~# ifconfig eth1 10.10.10.22 netmask 255.255.255.0 broadcast 10.10.10.255 up
Es necesario asegurar una configuración correcta de la direccion de broadcast (10.10.10.255) ya
que nuestra configuración de Heartbeat enviará los ''pulsos'' como paquetes UDP a
la dirección de broadcast.
- Asegurar un fichero
/etc/hosts con las direcciones correctas (ya hecho)
------Contenido-----
127.0.0.1 localhost
10.10.10.11 servidor1
10.10.10.22 servidor2
------Contenido-----
- Asegurar que los hostnames son los correctos
servidor1:~# hostname
servidor2:~# hostname
(si es necesario asignar los correctos con ''servidor1:~# hostname servidor1'' ó ''servidor2:~# hostname servidor2'')
- Diferenciar las webs por defecto de Apache (sólo para depuración y pruebas)
servidor1:~# nano /var/www/index.html
servidor2:~# nano /var/www/index.html
No es necesario arrancar los servidores Apache explícitamente (ya lo hará Pacemaker cuando ''toque'')
Heartbeat se encarga de gestionar los nodos del cluster y su estado (up/down)
- Editar configuración (en cualquier nodo)
servidor1:~# cd /etc/ha.d
servidor1:/etc/ha.d/# nano ha.cf
------Contenido-----
logfile /var/log/heartbeat.logfile
logfacility local0
autojoin none # Los nodos del cluster se declararan de forma estaica en
# los parametros "node" del fichero /etc/ha.d/ha.cf
bcast eth1 # Envio de "pulsos" (heartbeat) sobre eth1 en modo broadcast
# usando paquetes UDP (puerto 694 por defecto)
warntime 5
deadtime 15
initdead 60
keepalive 2 # "Pulsos" entre nodos (heartbeats) cada 2 segundos
node servidor1
node servidor2
pacemaker respawn
------Contenido-----
- Especificar claves de autenticación entre nodos
servidor1:/etc/ha.d/# nano authkeys
------Contenido-----
auth 1
1 sha1 unaclavecualquiera
------Contenido-----
Ajustar (en ambas máquinas) los permisos del fichero de claves (deben de permitir únicamente acceso para usuario root)
servidor1:/etc/ha.d/# chmod 600 authkeys
- Propagar la configuración a los demás nodos (se hace mediante SSH)
servidor1:/etc/ha.d/# /usr/share/heartbeat/ha_propagate
(pedirá la contraseña de root de cada máquina del cluster [purple])
Comprobar en el directorio /etc/ha.d de la máquina servidor2 que
realmente se han propagado los 2 ficheros (ha.cf, authkeys)
- Arrancar demonio heartbeat en todas las máquinas del cluster
servidor1:/etc/ha.d/# /etc/init.d/heartbeat restart
servidor2:/etc/ha.d/# /etc/init.d/heartbeat restart
Tardará hasta un minuto (parámetro initdead).
Se puede ver como se ''suman'' nodos al cluster con el comando crm_mon
servidor1:/etc/ha.d/# crm_mon
servidor2:/etc/ha.d/# crm_mon
(finalizar con CONTROL+C)
Al finalizar el ''arranque'' del cluster mostrará que hay configurados 2 nodos y 0 recursos,
indicando los nodos que están online (Online: [servidor1 servidor2])
servidor1:/etc/ha.d/# crm status
Pacemaker gestiona los recursos (servicios del cluster) y su asignación a los nodos.
En este ejemplo Pacemaker gestionará 2 recursos en modo activo-pasivo:
- la dirección IP pública 193.147.87.47 [recurso
DIR_PUBLICA]
- un servidor web Apache [recurso
APACHE]
- Entrar en la consola de configuración de Pacemaker [crm shell] (permite TAB para autocompletar)
servidor1:/etc/ha.d/# crm configure
crm(live) configure# show
crm(live) configure# show xml
- La configuración de Pacemaker reside en un documento XML, el CIB (Cluster Information Base)
[ubicación
/var/lib/heartbeat/crm/cib.xml]
- La consola crm shell permite editar las entradas de ese fichero (se escriben las modificaciones de
parámetros con el comando
commit).
- Más información y ejemplos: http://clusterlabs.org/wiki/Example_configurations
- Ajustar parámetros (deshabilitar STONITH y ajustar QUORUM)
crm(live) configure# property stonith-enabled=false
crm(live) configure# property no-quorum-policy=ignore
crm(live) configure# commit
crm(live) configure# show
- STONITH: mecanismo para ''matar'' nodos/recursos fallidos para que no entren en competencia
con los nodos/recursos que los reemplazan (evita inconsistencia de datos cuando dos componentes
del cluster pretenden realizar las mismas tareas)
- QUORUM: mecanismo de ''votación'' para determinar las acciones a realizar cuando hay conflicto entre
varios nodos (''gana'' la mayoría). En nuestro caso
con sólo 2 nodos, nunca habrá quorum (se ignoran esos ''no acuerdos'')
- Añadir el recurso
DIR_PUBLICA
- PREVIO: Desde la máquina cliente lanzar el comando ping a la dirección IP
193.147.87.47 (fallará hasta que el cluster la habilite)
cliente:~/# ping 193.147.87.47
- Revisar los parámetros del ''resource agent''
IPaddr
crm(live) configure# ra
crm(live) configure ra# list ocf
(muestra los ''agentes de recurso'' de Heartbeat/Pacemaker disponibles)
crm(live) configure ra# list lsb
(muestra los ''agentes de recurso'' del sistema disponibles [scripts en /etc/init.d])
crm(live) configure ra# info ocf:heartbeat:IPaddr
crm(live) configure ra# cd
- Darlo de alta y configurarlo con la IP pública del servidor web y el interfaz de red a usar
<OJO: todo en la misma linea>
crm(live) configure# primitive DIR_PUBLICA ocf:heartbeat:IPaddr
params ip=193.147.87.47 cidr_netmask=255.255.255.0 nic=eth0
crm(live) configure# commit
crm(live) configure# show
(comprobar el ping desde cliente [en algún momento empezará a responder])
- Comprobar con ''
crm status'' a qué nodo se le ha asignado el recurso DIR_PUBLICA
- En esa máquina ver la configuración de direcciones con ''
ifconfig -a'' (habrá creado y configurado un alias eth0:0)
- Añadir el recurso
APACHE
- Revisar los parámetros del ''resource agent
apache
crm(live) configure# ra
crm(live) configure ra# list ocf
crm(live) configure ra# info ocf:heartbeat:apache
crm(live) configure ra# cd
- Darlo de alta y configurarlo
crm(live) configure# primitive APACHE ocf:heartbeat:apache params configfile=/etc/apache2/apache2.conf
crm(live) configure# commit
crm(live) configure# show
- Desde otro terminal [
CONTROL+F2] o desde el otro nodo: comprobar cómo evoluciona el
estado del cluster [comando ''crm_mon'' ó ''crm status'']
- Puede suceder que el recurso
DIR_PUBLICA se asigne a un nodo y el recurso APACHE al otro
- Vincular los recursos
DIR_PUBLICA y APACHE (''co-localizar'' ambos recursos)
crm(live) configure# colocation APACHE_SOBRE_DIRPUBLICA inf: DIR_PUBLICA APACHE
crm(live) configure# commit
crm(live) configure# show
crm(live) configure# exit
- Comprobar cómo evoluciona el estado del cluster con el comando ''
crm_mon'' hasta que se estabilice y los
dos recursos se asignen al mismo nodo.
- Cuando los dos recursos migren al mismo nodo, comprobar el acceso al servidor web desde
la máquina cliente con
lynx o firefox (a 193.147.87.47)
- Forzar la migración de los recursos a otra máquina
servidor1:/etc/ha.d/# crm resource migrate APACHE servidorX
servidor1:/etc/ha.d/# crm status
- Detener la máquina donde se esté ejecutando (
servidorX) [o apagarla]
y comprobar que el otro servidor ocupa su lugar
servidorX: shutdown -h now
servidorY:~/# crm_mon (esperar hasta 10s [intervalo por defecto del agente de monitorización de apache]
ó 15s [param deadtime])
servidorY:~/# crm status
Cuando termine la migración, comprobar el acceso al servidor web desde
la máquina cliente con lynx o firefox
- Descripción breve del ejercicio realizado
- Detallar los pasos seguidos y los resultados obtenidos en las pruebas realizadas
Entrega: FAITIC
Fecha límite: <pendiente de determinar>
ribadas
2015-11-30