Práctica 2. Desarrollo de un sistema CBR con WEKA
El trabajo consistirá en implementar un prototipo de una herramienta de ayuda para la gestión de noticias.
Se seguirá el esquema de los sistemas CBR para auxiliar a los usuarios en las tareas de
identificar la temática de las noticias y asignarles una serie de palabras clave que las
describan.
- Cada noticia se corresponderá con un caso.
- La información de partida que conforma la descripción del caso es el título
de la noticia, un resumen y el texto completo de la misma.
- La salida a asociar a cada caso será el tema del texto y la lista de palabras clave.
No es necesario hacer pruebas para estudiar y ajustar los distintos parámetros posibles.
Sí se pide realizar una evaluación sencilla para ver como evoluciona el porcentaje de aciertos
y errores a medida que se van procesando los nuevos casos.
- Conocer el funcionamiento de los sistemas de razonamiento basado en casos (CBR)
- Usar las clases del API de WEKA para implementar los distintos componentes del CBR
Dado que se trata de un prototipo para mostrar el desarrollo de sistemas CBR, se harán
una serie de simplificaciones.
- Todas las noticias disponibles ya tienen asignado su correspondiente tema.
- El sistema a desarrollar omitirá esa información a la hora de procesar el
caso a resolver y propondrá su propio tema.
- Para simular la intervención del usuario en la fase de REVISIÓN si se tomará en
cuenta el tema ''real'' para decidir si la propuesta del sistema es un éxito
o un fracaso.
Cada caso está almacenado en un fichero XML (se aporta código para su lectura y escritura).
- Los ficheros XML de los casos que conforman la BASE DE CASOS están almacenados en el directorio
''base_casos'', que incialmente cuenta con 1000 casos.
- Los casos resueltos que se decida RETENER se incorporarán a ese directorio.
El funcionamiento de cada una de las fases del esquema CBR se describe en las siguientes secciones.
Pseudocódigo del ciclo CBR:
BaseCasos baseCasos = new BaseCasos();
baseCasos.inicializar(".../base_casos");
bucle:
CasoCBR casoResolver = new CasoCBR();
casoResolver.cargaXML(fichero);
casosSimilares = RECUPERAR(baseCasos, casoResolver);
CasoCBR casoResuelto = REUTILIZAR(casoResolver, casosSimilares);
CasoSBR casoRevisado = REVISAR(casoResuelto, temaReal);
RETENER(casoRevisado, baseCasos);
fin_bucle;
- La base de casos estará almacenada físicamente en el directorio ''base_casos''.
- Dentro de la aplicación la representación en memoria de la base de casos empleará una estructura
KDTree
de WEKA para agilizar la búsqueda.
- Cada caso estará representado en el KDTree por un objeto Instance
cuyo contenido corresponderá con valores (pesos) de las palabras extraidas del texto
de su
TITULO y RESUMEN.
Antes de iniciar el ciclo de CBR se deberá construir la representación en memoria de la base de casos a
partir del directorio ''base_casos''.
- Cargar los ficheros XML de la base de casos en un objeto Instances
con tres atributos de tipo String:
ID, TITULO y RESUMEN
- El atributo
ID será necesario en la fase de RECUPERACIÓN para identificar
el fichero XML de cada caso.
- Usar un filtro StringToWordVector para transformar los atributos
String
TITULO y RESUMEN en vectores de atributos numéricos.
- Crear un KDTree con el nuevo objeto Instances resultante de ese filtrado
Información sobre KDTree en WEKA:
weka.core.neighboursearch.KDTree
- Métodos de interés:
Instances kNearestNeighbours(Instance target, int k)
Returns the k nearest neighbours of the supplied instance.
void setDistanceFunction(DistanceFunction df)
sets the distance function to use for nearest neighbour search.
void setInstances(Instances instances)
Builds the KDTree on the given set of instances.
void update(Instance instance)
Adds one instance to the KDTree.
Se recuperarán los 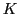 casos del KDTree que representa en memoria a la BASE DE CASOS
cuyos
casos del KDTree que representa en memoria a la BASE DE CASOS
cuyos TITULO y RESUMEN sea más similares a los
del caso a resolver. Los valores de a usar serán mayores o iguales a 15.
- Cargar el fichero XML del caso a resolver, extraer su
ID, TITULO y RESUMEN
y crear con ellos un objeto Instance.
- Pasar ese objeto Instance por el filtro StringtoWordVector
usado para crear el KDTree que almacena la Base de Casos (sección anterior).
Como resultado se obtendrá una instancia compatible con las
almacenadas en el KDTree (vectores numéricos)
- Consultar el KDTree para obtener las instancias más similares
al Instance filtrado.
- Usando sus atributos
ID se podrán identificar los ficheros XML correspondientes
a los casos similares localizados.
Los casos similares recuperados se utilizarán para identificar la temática del caso a resolver y para
asignarle sus palabras clave.
Se usará el TEXTO COMPLETO de los casos similares para entrenar un clasificador
maquina de vectores de soporte (SVM)
(clase weka.classifiers.functions.SMO
en WEKA). El atributo clase se construirá a partir del campo TEMA de cada uno de esos casos.
- Cargar los ficheros XML de los casos similares en un objeto Instances
con un atributo de tipo String
TEXTO y un atributo TEMA de tipo Nominal
que se marcará como atributo clase.
- Usar un filtro StringToWordVector para transformar el atributo
String
TEXTO en vectores de atributos numéricos.
- Hay que configurar el filtro StringToVordVector para evitar
que procese el atributo clase
TEMA.
- Entrenar el clasificador SMO con el dataset filtrado.
Con el TEXTO COMPLETO del caso a resolver se crea un objeto Instance.
La salida que ofrezca el clasificador para esa instancia se usará para asignar el tema del caso a resolver.
- Cargar el fichero XML del caso a resolver, extraer su texto completo
y crear un objeto Instance sin clase asignada.
- Pasar ese objeto Instance por el filtro StringtoWordVector
usado para crear el conjunto de entrenamiento para obtener una instancia compatible con
el clasificador SMO entrenado.
- Clasificar esa instancia con el clasificador SMO entrenado y asignar
como TEMA del caso a resolver el tema predicho por el clasificador.
Para implementar la asignación de palabras clave a la noticia se empleará un selector de atributos
(weka.attributeSelection.AttributeSelection).
- El selector se aplicará sobre el conjunto resultante de añadir el objeto Instance
del caso a resolver al objeto Instances que almacena el texto filtrado
de los casos similares (ambos creados en el paso previo).
- Los selectores de atributos emplean dos objetos WEKA:
- Puede usarse casi cualquier combinación de evaluador y buscador (usar el interfaz gráfico para
comprobar cuales son compatibles)
- Por ejemplo: weka.attributeSelection.Ranker
con weka.attributeSelection.GainRatioAttributeEval
- Aquellos atributos seleccionados que además estén presentes en el caso a resolver
(tienen valor no nulo en el objeto Instance) formarán la lista de PALABRAS CLAVE.
- Se tomarán sólo los 5 primeros atributos como PALABRAS CLAVE a asignar al caso a resolver
- Se recorrera la lista ordenada de atributos seleccionados tomando el nombre
de los 5 primeros que no tengan valor 0 en el objeto Instance
asociado al caso a resolver.
Se simulará la revisión por parte de un usuario humano empleando la información sobre el tema
del caso a resolver presente en su fichero XML.
- Comparar el tema propuesto por el clasificador SMO entrenado con los casos similares con
el ''tema real'' del caso a resolver (presente en el fichero XML).
- Si coinciden, el caso resuelto se etiqueta como EXITO. Si no, se etiqueta como FRACASO.
No se contempla el proceso de revisión sobre las palabras clave propuestas, la lista propuesta se aceptará
siempre como correcta.
Se implementará una aproximación inspirada en los métodos crecientes de selección de ejemplos.
- Todos los casos etiquetados como FRACASO, se recordarán con el valor correcto del campo
TEMA
del fichero XML.
- El proceso falló y es necesario tenerlo en cuenta ese caso
- Se recodará un caso etiquetado como éxito EXITO sólo cuando su TEMA no fuera el más
frecuente de entre
los temas de los casos similares recuperados.
- El proceso fue correcto, pero tiene poco respaldo en la Base de Casos (una votación
simple hubiera fallado) y es necesario contar con más muestras de ese tipo de casos.
En el directorio ''base_casos'' se guardará una copia del fichero XML del
caso revisado con la información definitiva que se ha generado.
Los casos recordados se introducirán también en el KDTree que representa
a la BASE DE CASOS en memoria.
- Crear un objeto Instance usando el Filtro StringToWordVector
sobre el texto del TITULO y RESUMEN del caso a resolver.
- Añadir el objeto Instance resultante al KDTree
Los filtros StringToWordVector se usan en las fases de Recuperación (con TITULO y RESUMEN)
y en la Reutilización (con TEXTO COMPLETO).
Esta clase tiene varios parámetros para controlar la forma de transformar un texto en un vector de palabras y el modo de asignar valores a los atributos (palabras) resultantes.
- En esta práctica es aconsejable usar listas de palabras vacías(stopwords) y algoritmos de
stemming.
- Se acompaña una lista de stopwords para el inglés y WEKA ofrece un algoritmo de stemming:
LovinsStemmer.
- Por defecto, en los objetos Instance resultantes los valores asociados a las palabras
son binarios (1 si está presente en el String, 0 si no).
- Se puede probar a usar valores no binarios en los atributos, cambiando el esquema de pesos:
TF-IDF).
Mas información:
StringToWordVector
Importante: El esquema descrito hace uso de clases que sólo están presentes en la versión 3.6.x
de Weka, que a su vez require usar la versión de Java 6.0 o superior.
- Corpus de noticias (formato XML), base de casos inicial y colección de casos para evaluación:
corpus.tgz
- Lista de temas posibles:
lista-temas.txt
- Lista de palabras vacias (stopwords):
stopwords
- Código de ejemplo para carga/escritura de casos en ficheros XML:
CasoCBR.java
- Información y ejemplos sobre el uso del API de Weka:
API WEKA
Práctica individual o en parejas.
Debe entregarse una memoria en papel (8-10 págs máximo) junto con el código fuente
en CD o enviado por e-mail.
Memoria: Se trata de una memoria descriptiva de la implementación.
No es necesario documentar aspectos teóricos.
Un esquema posible es:
- Descripción del problema a resolver y de los recursos disponibles (corpus)
- Descripción detallada de la solución implementada
- Heramientas usadas (APIs, etc)
- Estructura de la solución y estrategias seguidas
- Técnicas/herramientas de aprendizaje automática empleadas en cade etapa.
- Descripción detallada de las etapas del CBR y su implementación
- Documentar las pruebas realizadas, alternativas evaluadas y resultados obtenidos
- Posibles aspectos a evaluar en el preprocesamiento de los textos (configuración de StringToWordVector):
- Uso de stemming
- Uso de stop-words
- Esquema de asignación de pesos (booleano, tf, tf-idf)
- Posibles aspectos a evaluar en el funcionamiento del CBR
- Número de casos similares recuperados
- Problemas encontrados y soluciones adoptadas
- Conclusiones generales
Fecha límite de entrega: (07/05/2013)
Santiago Fernández Lanza
2013-01-07