Práctica 1. Uso de WEKA: Evaluacion de tecnicas de combinacion de clasificadores
El trabajo constará una evaluación de distintas técnicas de combinación de clasificadores supervisados. Para ello se utilizará como base el entorno WEKA
que implementa en Java distintas variantes de algoritmos de este tipo.
- Familiarizarse con el uso de una herramienta de aprendizaje automático como WEKA y con la colección de algoritmos que implementa.
- Conocer las técnicas de combinación de clasificadores y las ventajas que aportan
- Organizar experimentos para evaluar las características de distintos métodos de aprendizaje sobre diferentes conjuntos de entrenamiento.
Las tareas a realizar supondrán el uso del interfaz gráfico de WEKA para lanzar diversas tandas de aprendizaje-evaluación de los algoritmos a estudiar. Se evaluarán distintas combinaciones de parámetros para cada uno de los algoritmos estudiados con el objetivo de identificar los valores de los parámetros que ofrezcan mejor rendimiento.
En cuanto a los algoritmos a evaluar, serán los siguientes:
- Algoritmos de aprendizaje de árboles de decisión [algoritmo C4.5]
- La implementación de C4.5 en WEKA se llama J48 y se encuentra en el apartado TREES
- Algoritmos de aprendizaje por analogía, IBL (Instance Based Learning) [IBk] (apartado LAZY de WEKA)
- La implementación de IBk en WEKA se encuentra en el apartado LAZY
- Algoritmos de combinación de clasificadores mediante BAGGING
- La implementación de BAGGING en WEKA se encuentra en el apartado META
- Se deberá evaluar el uso de BAGGING para combinar clasificadores de tipo J48
y para combinar clasificadores de tipo IBk
- Algoritmos de combinación de clasificadores mediante BOOSTING
- En concreto se usará el algoritmo AdaBOOST
- La implementación de AdaBOOST en WEKA se encuentra en el apartado META
- Se deberá evaluar el uso de AdaBOOST para combinar clasificadores de tipo J48
y para combinar clasificadores de tipo IBk
En cuanto a los datos a utilizar en los experimentos, se utilizarán tres datasets. Dos de ellos forman parte
del repositorio UCI
(más detalles en la descripciones incluidas en el repositorio):
- Dataset 1: Automobile dataset. Categorización del nivel de riesgo para aseguradoras de coches en base a sus características.
[descripción]
- Dataset 2: Letter Recognition dataset. Reconocimiento de caracteres.
[descripción]
- NOTA: En la página de WEKA están disponibles estos datasets en el formato ARFF usado por la herramienta.
El tercer dataset no se encuentra en formato ARFF (será necesario crear un archivo ARFF conforme a las indicaciones que se proporcionan)
Las tareas concretas a realizar serán las siguientes:
- Se evaluarán de forma aislada los algoritmos J48 y IBk para identificar las configuraciones más
beneficiosas de cada algoritmo para cada uno de los tres datasets.
- Se comprobará si los resultados obtenidos mejoran al emplear BAGGING y BOOSTING para combinar cada uno de los
clasificadores básicos (C4.5 e IBk) y se identificarán las configuraciones de BAGGING y BOOSTING con mejores resultados.
En cada caso, se realizara una evaluación de diferentes configuraciones, variando los distintos parámetros que rigen el funcionamiento de los algoritmos de aprendizaje.
Para la evaluación de los resultados del aprendizaje se usarán las propias medidas de rendimiento (% aciertos y % errores, etc) que proporciona el interfaz de WEKA.
Práctica individual o en parejas.
En la memoria de la práctica se debe incluir:
- Descripción BREVE de los datasets utilizados
- Descripción general de los métodos de combinación de clasificadores estudiados (BAGGING y ADABoost)
- Descripción del estudio y de las pruebas realizadas.
- Describir los parámetros más importantes que WEKA permite modificar WEKA para ajustar cada uno de los algoritmos,
indicando los que se han tenido en cuenta en los experimentos
- Indicar los métodos concretos de evaluación utilizados.
- Describir la estructura del conjunto concreto de pruebas realizadas (valores de parámetros estudiados, etc)
- Resultados obtenidos
- Conclusiones y comentarios de los resultados
- Referencias bibliográficas empleadas
FECHA LIMITE DE ENTREGA: (07/05/2013)
Además del uso directo del API de programación de WEKA que se revisará en la segunda práctica,
el interfaz gráfico de WEKA
ofrece 4 modos de funcionamiento [Applications] (ver manual completo en PDF):
- Explorer.
- Interfaz básico para usar el conjunto de algoritmos que ofrece WEKA (clasificación, clustering, reglas de asociación, selección de atributos y visualización)
- Experimenter.
- Interfaz gráfico para automatizar baterías de experimentos
- Knowledge Flow.
- Interfaz gráfico para diseñar flujos y procesos donde se combinen varios componentes para conformar aplicaciones complejas.
- Simple CLI.
- Acceso los algoritmos de WEKA desde un interfaz de línea de comandos.
Para realizar esta práctica se empleará el interfaz Explorer
(ver presentación PPT), si se hacen las pruebas ''manuales'', o el interfaz Experimenter, si se desean automatizar las pruebas.
Las funcionalidades del interfaz Explorer se organizan en 6 pestañas:
- Preprocess.
- Carga de los datasets a emplear y procesamiento previo a la aplicación de los algoritmos de aprendizaje
- Permite cargar datos desde ficheros ARFF,
ficheros CSV y bases de datos (mediante JDBC)
- Permite aplicar distintos filtros sobre los datos cargados: selección de atributos,
selección de instancias, modificación/transformación de atributos (conversión
numérico-nominal, conversión texto-vector_numérico, etc), ...
- Permite seleccionar manualmente los atributos a emplear y analizar su distribución.
- Classify.
- Interfaz de experimentación con algoritmos de clasificación
- Permite seleccionar un clasificador (botón [Choose]) y configurar sus parámetros (pulsando sobre el nombre del algoritmo)
- Permite especificar el método de evaluación (Test options)
- Training set.
- Usa los mismos datos para el entrenamiento y para la evaluación
- Supplied test set.
- Usa un nuevo fichero ARFF para realizar la evaluación
- Cross validation.
- Divide los datos disponibles en
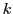 grupos y realiza tandas entrenamiento-evaluación
diferentes, usando
grupos y realiza tandas entrenamiento-evaluación
diferentes, usando 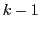 grupos para entrenar y el restante para la validación.
grupos para entrenar y el restante para la validación.
- Percentage split.
- Divide los datos disponibles en un grupo de entrenamiento (en base al porcentaje indicado)
y en otro grupo de evaluación
- Permite establecer el atributo clase sobre el que realizar el aprendizaje
- Muestra los resultados del proceso entrenamiento-evaluación
- Cluster.
- Interfaz de experimentación con algoritmos de clustering
- Associate.
- Interfaz de experimentación con algoritmos para aprendizaje de reglas de asociación
- Select attributes.
- Interfaz de experimentación con algoritmos de selección de atributos
- Visualize.
- Interfaz para la visualización de datasets, relaciones entre atributos, etc
Importante:
- Para obtener resultados realmente significativos y comparables se deberá usar en todas las pruebas el mismo método de evaluación
(Percentage split o Cross validation), con los mismo parámetros.
- En el caso concreto de esta práctica, bastará con utilizar el porcentaje de aciertos y errores como criterio de comparación, no es necesario usar otras medidas más complejas.
|
|
Información sobre WEKA
Datos de entrenamiento
Santiago Fernández Lanza
2013-01-07