- cliente (193.147.87.33)
- servidor1 (10.10.10.11)
- servidor2 (10.10.10.22)
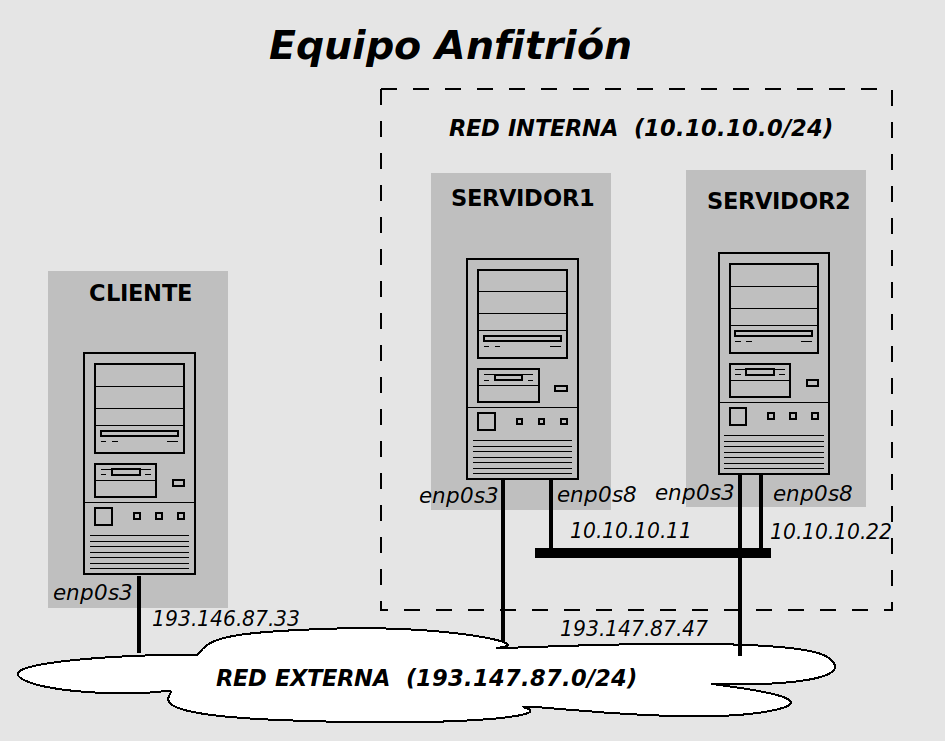
Ejemplo de cluster de alta disponibilidad en modo activo-pasivo utilizando LinuxHA.
Recursos complementarios
En estas prácticas se empleará el software de virtualización VIRTUALBOX para simular los equipos GNU/Linux sobre los que se realizarán las pruebas.
alumno@pc: $ sh ejercicio-linuxha.sh
Powershell.exe -executionpolicy bypass -file ejercicio-linuxha.ps1
Notas:
$DIR_BASE especifica donde se descargarán las imágenes y se crearán las MVs.
Por defecto en GNU/Linux será en $HOME/CDA2223 y en Windows en C:/CDA2223.
Puede modificarse antes de lanzar los scripts para hacer la instalación en otro directorio más conveniente (disco externo, etc)
.vdi.zip de http://ccia.esei.uvigo.es/docencia/CDA/2223/practicas/ y copiarlos en el directorio anterior ($DIR_BASE) para que el script haga el resto.
VBoxManage startvm <nombre MV>_<id>
Contiene un sistema Debian 11 con herramientas gráficas y un entorno gráfico ligero LXDE (Lighweight X11 Desktop Environment) [LXDE].
| login | password |
|---|---|
| root | purple |
| usuario | usuario |
(con permisos para sudo) |
root@datos:~# startx
Dispositivos -> Portapapeles compartido -> bidireccional de la ventana de la máquina virtual.
Linux-HA (High-Availability Linux) ofrece una colección de herramientas para desplegar cluster de alta disponibilidad en GNU/Linux, FreeBSD y otros entornos UNIX-like.
Detalles en https://clusterlabs.org/
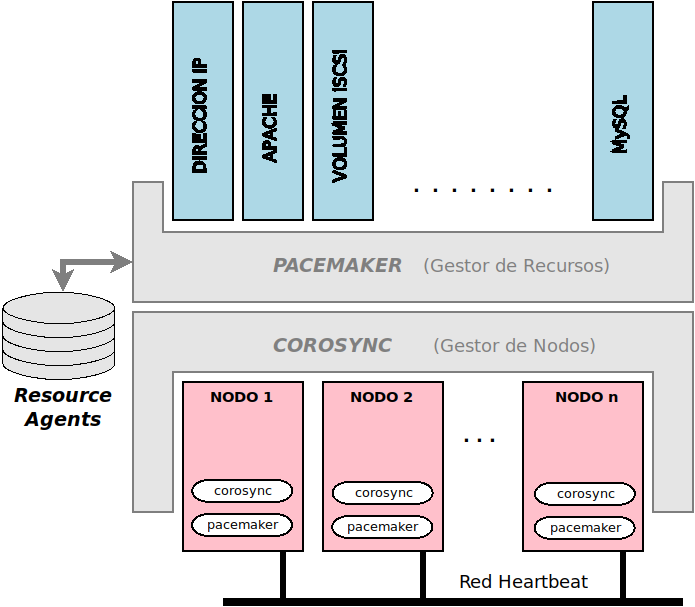
Gestor de nodos: componente responsable de monitorizar y gestionar los nodos que forman parte del cluster HA
Gestor de recursos: componente responsable de asignar ”recursos” a los nodos del cluster HA
Web: https://clusterlabs.org/pacemaker/
Resource agents: colección de scripts shell responsables de controlar los ”recursos” gestionados por el cluster HA
Colección de scripts para el control de ”recursos” o servicios (evolución de los agentes LSB).
Estandariza las acciones (start, stop, status, monitor, ..) sobre los ”recursos”, el paso de parámetros y los códigos de salida de los scripts.
Agentes de recursos disponibles: https://github.com/ClusterLabs/resource-agents/
Se corresponden con los scripts de arranque de los servicios del sistema (disponibles en /etc/init.d)
Suelen ser proporcionados por la distribución del sistema operativo utilizado.
resource-agents, instalados en /usr/lib/ocf/resource.d/heartbeat
apt-get install corosync cluster-glue apt-get install pacemaker resource-agents crmsh
------Contenido----- 127.0.0.1 localhost 10.10.10.11 servidor1 10.10.10.22 servidor2 ------Contenido-----
Asegurar también que los hostnames son los correctos
servidor1:~# hostname servidor2:~# hostname(si es necesario asignar los correctos con los comandos 1”hostname servidor1” ó ”hostname servidor2”)
servidor1:~# nano /var/www/html/index.html servidor2:~# nano /var/www/html/index.html
servidor1:~# systemctl stop apache2 servidor2:~# systemctl stop apache2
Corosync se encarga de gestionar los nodos del cluster y su estado (up/down)
|
|
servidor1:~# corosync-keygen Corosync Cluster Engine Authentication key generator. Gathering 2048 bits for key from /dev/urandom. Writing corosync key to /etc/corosync/authkey.
servidor1:~# cd /etc/corosync
servidor1:/etc/corosync/# mv corosync.conf corosync.conf.orig
servidor1:/etc/corosync/# nano corosync.conf
------ Contenido a incluir -----
## Configuración de la comunicación entre nodos (knet sobre udp con pulsos/mensajes cifrados y autenticados)
totem {
version: 2
cluster_name: clustercda
transport: knet
knet_transport: udp
crypto_cipher: aes256
crypto_hash: sha256
interface {
linknumber: 0
bindnetaddr: 10.10.10.0
mcastport: 5405
}
}
## Esquema de quorum (con 2 nodos no tiene sentido y la opción two_node:1 lo deshabilita)
quorum {
provider: corosync_votequorum
expected_votes: 2
two_node: 1
}
## Lista explicita de nodos que forman el cluster HA
nodelist {
node {
nodeid: 1
name: servidor1
ring0_addr: 10.10.10.11
}
node {
nodeid: 2
name: servidor2
ring0_addr: 10.10.10.22
}
}
logging {
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: yes
timestamp: on
}
------ Contenido a incluir -----
Nota: Más información en http://corosync.github.io/corosync/. Lista completa de parámetros en ayuda en línea (man)
servidor1:~/# man corosync_overview servidor1:~/# man corosync.conf servidor1:~/# man votequorum
servidor1:/etc/corosyncs/# scp {corosync.conf,authkey} root@servidor2:/etc/corosync
(pedirá la contraseña de root de cada máquina del cluster [purple])
Comprobar en el directorio /etc/corosync de la máquina servidor2 que realmente se han copia los 2 ficheros (corosync.conf, authkeys) con los permisos correctos.
|
|
Se puede ver como se ”suman” nodos al cluster con el comando crm_mon (desde cualquier nodo)
servidor1:~/# crm_mon (también crm_mon --show-detail)
servidor2:~/# crm_mon
(finalizar con CONTROL+C)
Al finalizar el ”arranque” del cluster (tardará un tiempo) mostrará que hay configurados 2 nodos y 0 recursos, indicando los nodos que están online (Online: [servidor1 servidor2])
servidor1:~# crm status
NOTA 1: Es posible que se muestren nodos adicionales en estado offline. Se trata de ”restos” de la configuración inicial de corosync existente en la imagen base de las máquinas virtuales.
NOTA 2: Para el desarrollo de la práctica lo más cómodo es dejar el comando crm_mon ejecuándose en una ventana propia y así poder comprobar la evolución y el estado del cluster en cualquier momento.
 A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al iniciar el demonio
A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al iniciar el demonio corosync en todos ellos?
Pacemaker gestiona los recursos (servicios del cluster) y su asignación a los nodos.
crm: man crm
En este ejemplo Pacemaker gestionará 2 recursos en modo activo-pasivo:
DIR_PUBLICA]
APACHE]
La consola de administración de Pacemaker (comando crm) tiene dos modos de uso (ambos equivalentes)
servidor1:# crm configure crm(live) configure# show crm(live) configure# show xml
Nota: En ”modo comando” se ejecutaría desde el intérprete de comandos del sistema el comando crm configure show.
crm(live) configure# property stonith-enabled=false crm(live) configure# property no-quorum-policy=ignore crm(live) configure# commit crm(live) configure# show
DIR_PUBLICA
Se definirá un ”recurso” que se corresponde con la asignación de una dirección IP pública (193.147.87.47) a uno de los equipos del cluster.
cliente:~/# ping 193.147.87.47
crm(live) configure# ra
crm(live) configure ra# list ocf
(muestra los ”agentes de recurso” Heartbeat/Pacemaker de tipo OCF disponibles [los scripts fueron instalados con 'apt-get install resource-agentes en /usr/lib/ocf/resource.d/heartbeat/])
crm(live) configure ra# list lsb
(muestra los ”agentes de recurso” correspondientes a scripts de arranque de tipo init [scripts en /etc/init.d, controlados con 'service <script> start|stop|restart ]')
crm(live) configure ra# list systemd
(muestra los ”agentes de recurso” correspondiente a servicos del systema gestionados por systemd [controlados con 'systemctl start|stop|restart <servico>)
crm(live) configure ra# info ocf:heartbeat:IPaddr (regreso al terminal con letra Q)
crm(live) configure ra# up
(ojo con el separador de líneas \)
SINTAXIS: primitive <nombre-recurso> <class>:<provider>:<nombre> [params <atributo>=<valor>]
crm(live) configure# help primitive (regreso al terminal con letra Q)
crm(live) configure# primitive DIR_PUBLICA ocf:heartbeat:IPaddr \
params ip=193.147.87.47 cidr_netmask=255.255.255.0 nic=enp0s3
crm(live) configure# commit
crm(live) configure# show
(comprobar el ping desde cliente [en algún momento empezará a responder])
crm status” o ”crm_mon” a qué nodo se le ha asignado el recurso DIR_PUBLICA
ip address” (habrá vinculado a la tarjeta enp0s3 la dirección 193.147.87.47)
A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al hacer commit y declarar el recurso DIR_PUBLICA?
APACHE
Se definirá un ”recurso” que se corresponde con la ejecución de un servidor HTTP Apache.
APACHE
crm(live) configure# ra list ocf crm(live) configure# ra info ocf:heartbeat:apache
crm(live) configure# primitive APACHE ocf:heartbeat:apache \
params configfile=/etc/apache2/apache2.conf
crm(live) configure# commit
crm(live) configure# show
crm_mon” ó ”crm status”]
DIR_PUBLICA se asigne a un nodo y el recurso APACHE al otro
DIR_PUBLICA y APACHE (”co-localizar” ambos recursos)
SINTAXIS: colocation <nombre> <score>: <nombre-recurso> <nombre-recurso>
!
crm(live) configure# help colocation crm(live) configure# colocation APACHE_SOBRE_DIRPUBLICA inf: DIR_PUBLICA APACHE crm(live) configure# commit crm(live) configure# show
crm_mon” hasta que se estabilice y los
dos recursos se asignen al mismo nodo.
193.147.87.47)
A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al hacer commit e incluir la restricción de ”colocalización” APACHE_SOBRE_DIRPUBLICA?
Desde el contexto resource del ”modo interactivo”
SINTAXIS: move <nombre-recurso> <nodo>
crm(live)configure# up crm(live)# resource crm(live)resource# help move crm(live)resource# move APACHE servidorX
Directamente con el ”modo comando” de crm desde línea de comandos
servidor1:~# crm resource move APACHE servidorX servidor1:~# crm status
A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al ejecutar el comando move del contexto resource?
servidorX:~/# shutdown -h now # MEJOR: apagar la MV desde el boton "Cerrar"
servidorY:~/# crm_mon (o crm --show-detail)
[esperar hasta que detecte el fallo y migre recursos]
ó
servidorY:~/# crm status
Cuando termine la migración, comprobar el acceso al servidor web desde
la máquina cliente con lynx o Falkon.
A INCUIR EN EL ENTREGABLE: ¿Qué ha pasado en los nodos del cluster al apagar la máquina con los recursos DIR_PUBLICA y APACHE?
Volver a ”encender” la máquina apagada y comprobar que sucede.
NOTA: En el fichero de LOG /var/log/corosync/corosync.log (disponible en los dos nodos) se puede ver la evolución del cluster, los eventos y las decisiones tomadas por los nodos del cluster.
Detallar los pasos seguidos y los resultados obtenidos en los siguientes puntos del ejemplo (señalados con A INCLUIR EN EL ENTREGABLE):
DIR_PUBLICA (punto 3 en la sección 4.3)
APACHE y establecimiento de la
restricción de ”co-localización” (punto 4 en la sección 4.3)
APACHE a otro nodo (punto 5 en la sección 4.3)
En cada uno de esos puntos a explicar:
crm status o crm_mon)
Entrega: MOOVI
Fecha límite: hasta el domingo 27/11/2022